

Authentication
The API requires authentication via inRiver REST API key, sent as header param Authorization.
curl -X GET "https://proxy.de/rest/../model/cvl/ResourceView" -H "accept: application/json" -H "Authorization: <InRiverRESTAPIKey>"
In SwaggerUI, this can be performed via

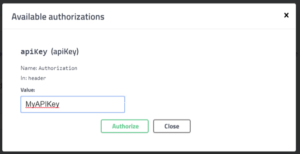
For convenienve, as alternative also Basic authentication is required. From the credentials entered for visually inspecting Swagger, the password part is interpreted as inRiver REST API Token
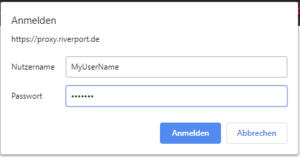
This way - for developers - it is easy to save credentials in the browser. "Try it out" will work without additional upfront "Authorize".
Data Model Access
Via entities resource, all specified entities including their attributes / value types can be obtained: 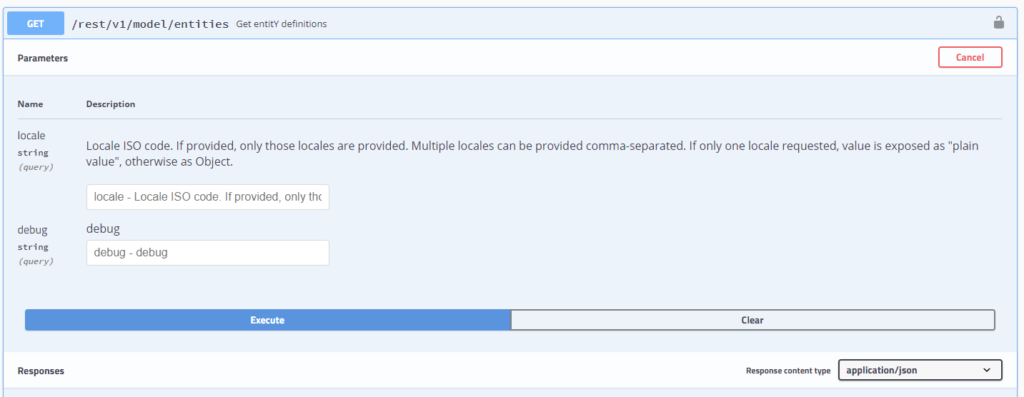
Example:
[ { "id": "Task", "attributes": [ { "id": "TaskDownloadType", "type": "CVL", "cvlId": "TaskDownloadType" }, { "id": "TaskCampaigns", "type": "Relation", "relationTargetTypeId": "Campaign" }, ...},{"id": "Resource", "attributes": [ { "id": "ResourceFilename", "type": "String" }, { "id": "ResourceLanguages", "type": "CVL", "multivalue": true, "cvlId": "Language" }, { "id": "ResourceMimeType", "type": "String" }, { "id": "ResourceFileId", "type": "File" }, ...]
For the CVL values - either individually or collectively, via cvl or cvls, all values can be fetched:
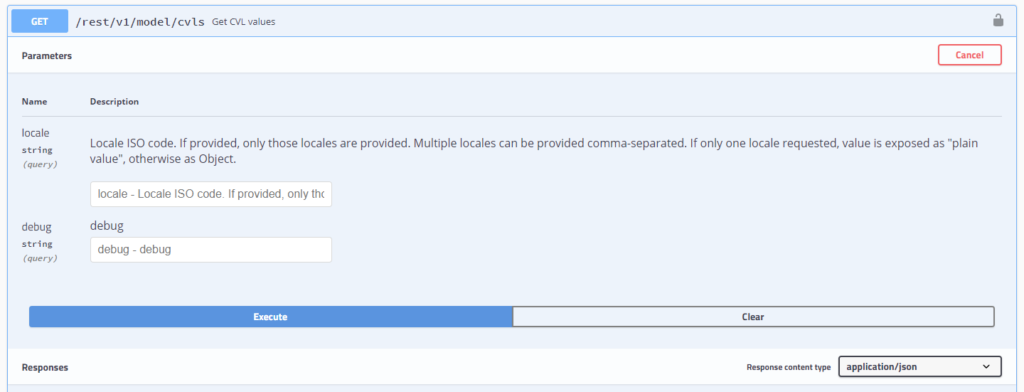
Example:
{ "MaterialProductGroup": { "id": "MaterialProductGroup", "values": [ { "#": "UWE", "en": "Underwear","de": "Unterwäsche" }, { "#": "SET", "en": "Sets" }, { "#": "SWI", "en": "Swimwear" },
Data Read Access
The core design principle of Canonical data format is to access data based on semantic values, i.e. instead of "entityId=12345" data is identified by the "real" unique (or non-unique) values, for example a product code or a color code. To conveniently access those entities, various endpoints are provided, encoding the key-value-pairs for filtering as part of the URL. This does not only make it conventient to code and diagnose - it is also in-line with typical REST standards. A receiving party does not need to work with sophisticated POST query documents and then to access data, simple queries look like:
https://proxy.riverport.de/rest/v1/entities/Material/MaterialSAPMaterialNo/10120015 https://proxy.riverport.de/rest/v1/entities/Resource/ResourceView/F https://proxy.riverport.de/rest/v1/entities/Resource/ResourceFilename/f.jpg/ResourceView/F
This will return - either as CSV, Excel or JSON, all entities matching those conditions. If the attribute is unique, an one-element array is returned.
Example:
[
{
"$enrichURL": "https://inrivereuw.productmarketingcloud.com/app/enrich#entity/999999999",
"MaterialSeriesName": "My Comfort",
"MaterialProductHierarchy": "abc",
"MaterialBrand": {
"#": "MyBrand"
},
"MaterialLastModified": "2019-12-29T16:53:03.0000000",
"$resourceURL": "https://asset.productmarketingcloud.com/api/assetstorage/xxx-xxx-xx-xx-xx-xx",
"$displayDescription": "MyComfort X",
"MaterialGender": {
"#": "FA"
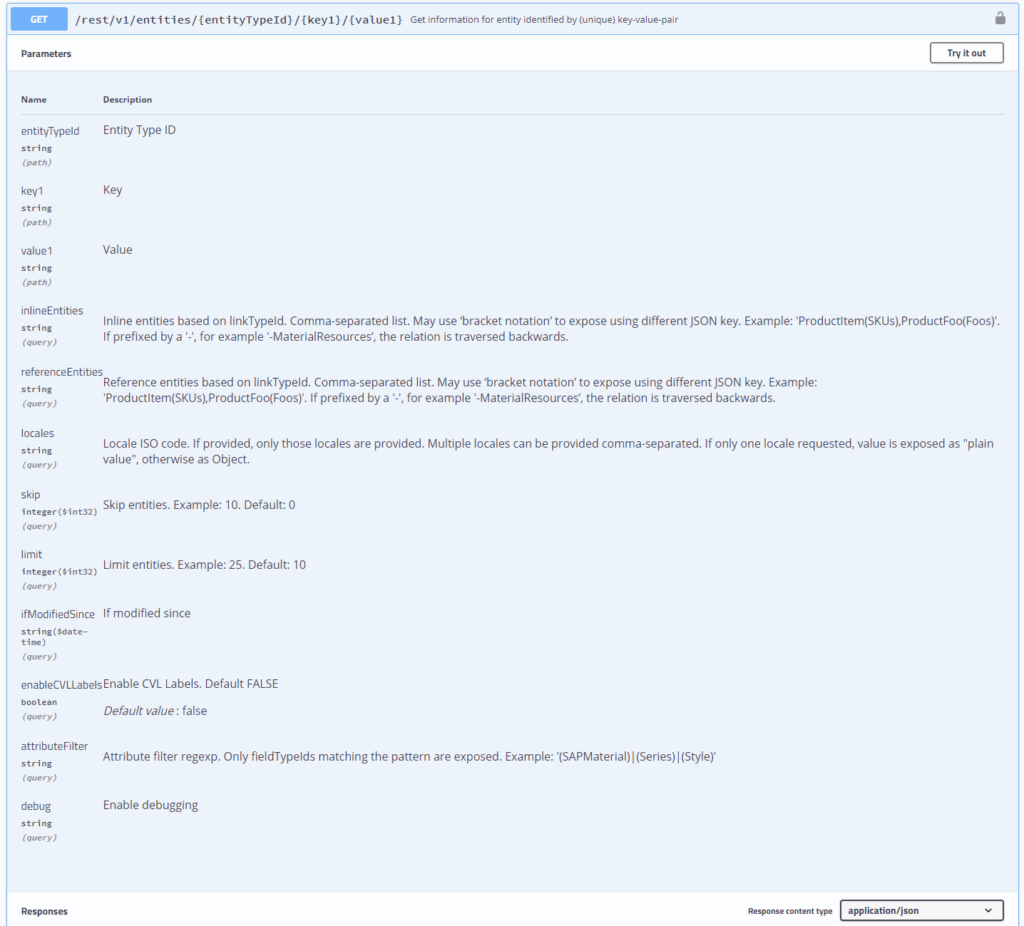
},To configure the representation of the entities, following parameters are supported - please refer to OpenAPI for technical details:
entityTypeId: inRiver Entity type ID.key1 / value1 / key2 / value2 / ...: Key-value-pairs of filter conditionsinlineEntities: Comma-separated list of relations that should be "inlined". If, for example, relation "myBs" is defined as "A's include B's", the returned object will contain an attribute "myBs" where the value is the array of "inlined" entities. For inlined entities, the same Canonical Model is applied, so even deeper-nested entities can be easily inlined. In the wild, this may be a "Product" including some "Colors" including some "Sizes" including some "Packaging Types".
The nested data structure makes it very convenient for additional mappings in middlewares like SAP PI/PO, Mulesoft, Boomi etc.
Example:
[{"$enrichURL": "https://inrivereuw.productmarketingcloud.com/app/enrich#entity/9999","MaterialSeriesName": "xxx",..."MaterialColors": [{"$enrichURL": "https://inrivereuw.productmarketingcloud.com/app/enrich#entity/99991","ColorTAG": [{"#": "TRN72"}],"ColorSKUPLCStatuses": [{"$enrichURL": "https://inrivereuw.productmarketingcloud.com/app/enrich#entity/99992","StatusTag": [{"#": "Best"}],...},{"$enrichURL": "https://inrivereuw.productmarketingcloud.com/app/enrich#entity/99996","ColorTAG": [{"#": "TRN73"}],]}]
referenceEntities: If not all data is required for nested entities, the relations may be listed as "referenceEntities". This saves a lot of roundtrip to inRiver and yields in smaller payload files. For all "included" entities, only displayName and displayDescription are exposed.
It is therefore recommended to configure those entities in a way that a business-relevant (unique) attribute is set as either name or displayName. Typical scenario: Reference to upsell / downsell products.
Example:
[
{
"$enrichURL": "https://inrivereuw.productmarketingcloud.com/app/enrich#entity/9999",
"MaterialSeriesName": "My Prod",
...
"MaterialColors": [
{
"$enrichURL": "https://inrivereuw.productmarketingcloud.com/app/enrich#entity/99991",
"$modifiedDate": "2019-12-29T14:53:00.0000000",
"$version": "1",
"$resourceURL": "https://asset.productmarketingcloud.com/api/assetstorage/xxx",
"$displayName": "My Prod A",
"$displayDescription": "10000003"
},
{
"$enrichURL": "https://inrivereuw.productmarketingcloud.com/app/enrich#entity/99992",
"$modifiedDate": "2019-12-29T14:53:00.0000000",
"$version": "1",
"$resourceURL": "https://asset.productmarketingcloud.com/api/assetstorage/xxx",
"$displayName": "My Prod B",
"$displayDescription": "10000004"
}, ...
]
]
- Relation direction: For both parameters listed above, it is possible to "reverse" the direction of lookup by prefixing a minus (-) sign. If a relation
A->Bis defined as "myBs", a value "-myBs" will expose an attributeB.myBs: [ <listOfAs> ] locales: Comma-separated list of inRiver language codes, ideally modeled as Locales. Defines which translations of LocaleString and CVL will be exposed.skip/limit: Similar to OData resources, defines the "window" of results to be be loaded. Required to allow server-side pagination. For example skip=10, limit=20 will fetch entities 10-20ifModifiedSince: Currently not fully supported due to issues with inRiver REST API. As workaround a custom field on every attribute may be defined like "lastModified" and updated via Entity and Relation Listener to cascade "dirty" detection.enableCVLLabels: If enabled, CVL values are not only exposed as{ "#": <id> }reference but with corresponding localizations as specified bylocales.attributeFilter: Regular expression to limit attributes to be returned. Note that this allows nifty filter conditions if the naming follows some naming convention:- (SAPMaterial)|(Series)|(Style)
- (^Material)|(^Resource)
- Material.*
Output Formats
Currently the REST proxy allows returing of data in JSON, CSV and Excel format.
For tabular data, entity information is "denormalized", i.e. shared data - as from parent entity - is exported multiple times.
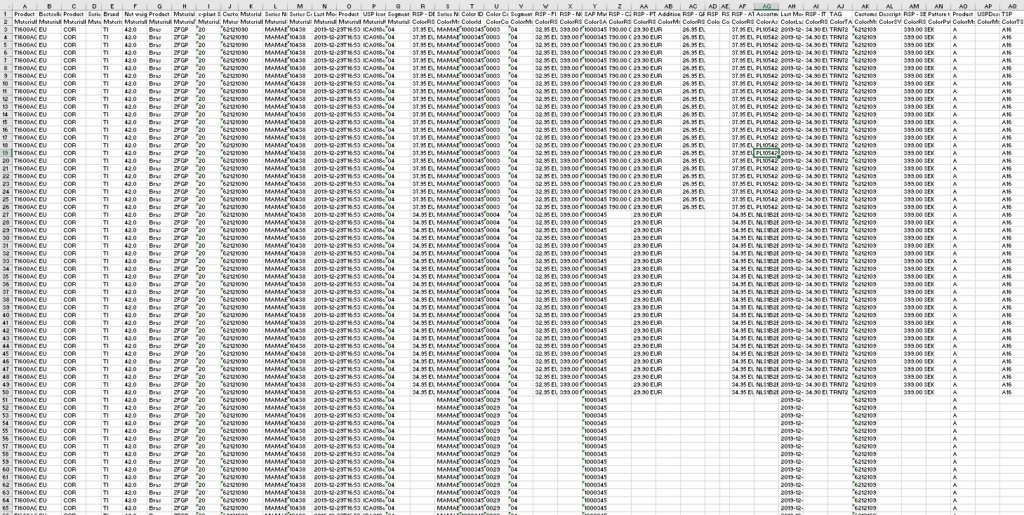
Note that this provides similar flexibility as the Content Store - but allows technical integration via middleware or by providing an Excel download link to inRiver users:
https://proxy.....de/rest/.../entities/Material/MaterialSAPMaterialNo/10003457?inlineEntities=MaterialColors&skip=0&limit=10
Non-Functional Aspects
- All data model and CVL data is cached - per API key.
- Monitoring information - including the actual processing time it took on inRiver side - accessible via
monitoringresource. - Multi-threaded, highly parallelized fetching of inRiver data. This reduces the waiting time significantly as typically more around 20 requests are executed simultaneously and weaved together once obtained.
- Full streaming mode: The resulting document is not assembled in memory but directly released to the client in increments. This allows extremely large payload files (for example: Downlod a complete channel) and reduces server resource needs.
- If for, whatever reason, downloads are aborted, also pending inRiver requests are aborted subsequently, i.e. no risk of "runaway" workers.
Known Limitations
- Currently inRiver does not disclose all data model details, for example no type "BLOB" for JSON documents inlined to represent - similar to XML - SKU data.
To allow seamless handling of BLOB data, the proxy automatically treats defined attributes as inline BLOBs and exposes them as part of the outer JSON object. - UPSERTing entities not ready for production use.
- Ordering of results obtained cannot be influenced (yet)